
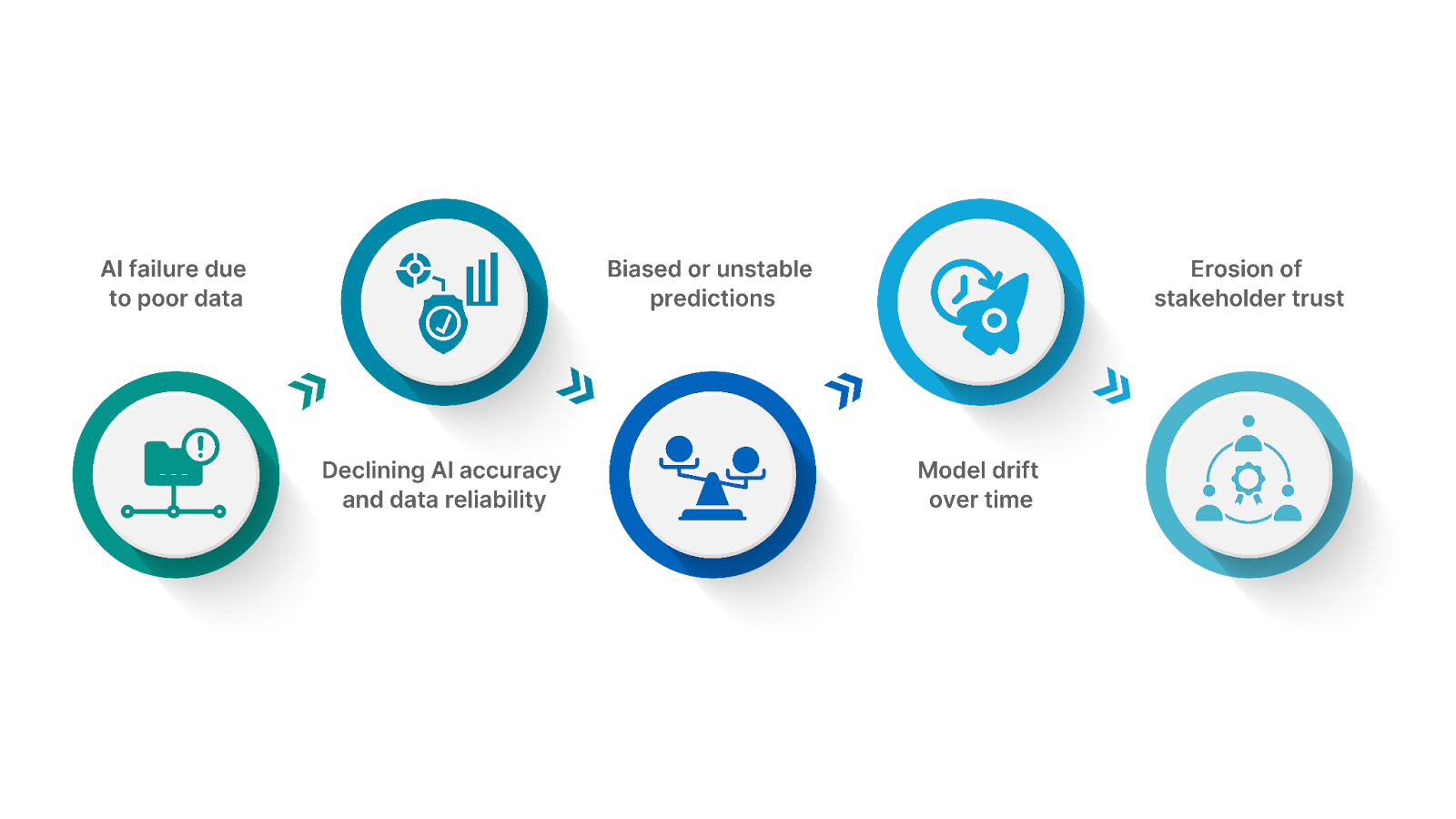
AI rarely fails dramatically. It fails quietly.
The dashboard still loads. The model still runs. Predictions still generate. But decisions start feeling “off.” Business teams question the outputs. Confidence fades.
Here’s the uncomfortable truth: AI failures usually begin in the data layer, not the model layer. If you want reliable AI, you need to understand one principle clearly:
AI model performance and data quality are inseparable.
Let’s unpack what that really means, and how to fix it at scale.
The Real Reason Behind AI Failures
Artificial intelligence doesn’t understand context. It understands patterns. And those patterns are entirely shaped by the data it sees. When artificial intelligence data is incomplete, inconsistent, biased, or outdated, the model absorbs those flaws as truth. The result?
Real-World Scenario 2: Banking Fraud Detection Failure
A bank deploys an AI model to detect fraudulent transactions in real time.
The Importance of Data Quality in AI Success
Clean data for machine learning is not just about removing duplicates. It means the data is:

Data-driven AI depends on structured data quality management. Without it, AI becomes fragile.
Scaling AI with trusted data requires a deliberate framework, not reactive cleanup when things go wrong.
How to Fix Data Quality Issues in AI Projects
Now let’s move from diagnosis to action. Fixing AI data problems in large organizations requires a systemic shift, from treating data as an input to treating it as infrastructure.
Below are the critical steps organizations must follow to build scalable, reliable AI supported by strong data foundations.
Step 1. Build a Data Quality Framework for Enterprise AI
Every successful AI project begins with a framework. A data quality framework provides clear ownership, accountability, measurable quality, and validation thresholds throughout the enterprise. Rather than debating what constitutes “good data” after the fact, when something has gone wrong, teams work within established parameters and quality KPIs. This allows data quality management to transition from reactive clean-up to a governed process – where AI accuracy and data quality are designed from the outset.
👉 How ChainSys Enables This: ChainSys enables this by embedding governance, ownership controls, policy-driven rules, and measurable quality standards directly into the enterprise data architecture through its Smart Data Platform.
Step 2. Automate Data Validation for AI Pipelines
It is not possible to scale manual validation. Data validation must be incorporated directly into the ingestion and transformation layers to identify problems before AI models are exposed to flawed data. Automated schema validation, anomaly detection, drift analysis, and duplicate detection eliminate the possibility of silent failure and AI system failure brought on by faulty data.
👉 How ChainSys Enables This: ChainSys dataZen automates schema checks, anomaly detection, drift monitoring, and rule enforcement within data pipelines to ensure flawed data never reaches AI models.
Step 3. Strengthen AI Training Data Quality
The long-term accuracy of the AI model is directly correlated with the caliber of the training data used in AI development. The accuracy of the AI model will gradually decline if the training data is of poor quality, such as incomplete historical data, unbalanced samples, or unstandardized labeling. Building a long-term accuracy foundation requires data versioning, balanced samples, standardized labeling, and validated retraining cycles.
👉 How ChainSys Enables This: ChainSys enhances the quality of training data through standardized data modeling, data harmonization, data lineage, and governed dataset versioning.
Step 4. Implement Continuous Data Cleansing for AI Systems
As business rules change and systems become more complex, data will unavoidably deteriorate. Data cleaning needs to be a continuous procedure. As systems become more complex, data will remain clean and consistent through ongoing data normalization, deduplication, enrichment, and reference alignment.
👉 How ChainSys Enables This: ChainSys Data Quality Management solution delivers continuous, rule-driven normalization, deduplication, enrichment, and reference alignment to maintain clean, consistent data as systems scale.
Step 5. Deploy Data Observability in AI Models
Merely keeping an eye on model metrics is insufficient. The state of the data layer itself must be visible. Teams can identify degradation before it impacts business by monitoring data freshness, feature shifts, missing values, and lineage changes in real-time.
👉 How ChainSys Enables This: ChainSys provides real-time data observability with freshness monitoring, anomaly alerts, and end-to-end lineage visibility to detect and prevent silent data degradation early.
The Role of ChainSys
Manual controls just cannot keep up with the growth of AI initiatives across departments, regions, and systems. The quality of AI data is negatively impacted by the gaps created by spreadsheets, disjointed validation scripts, and isolated governance tools.
This is addressed at the architectural level by ChainSys. The entire data layer on which AI relies is intended to be unified by the ChainSys Smart Data Platform. Rather than treating quality as a distinct cleanup task, it incorporates:
Why ChainSys vs. Traditional Approaches
Reliable AI Starts with the Right Foundation
AI doesn’t fail at scale because of algorithms. It fails because of unmanaged data. Fix the data layer, and AI stops being an experiment and starts becoming a system you can trust. Sustainable, data-driven AI requires a structured data quality framework, automated validation, strong AI training data quality, continuous cleansing, and real-time observability. Without that foundation, scaling AI with trusted data is nearly impossible.
If you want AI that performs consistently at scale, strengthen the data layer first.
Choose ChainSys. Build AI on data you can trust.













